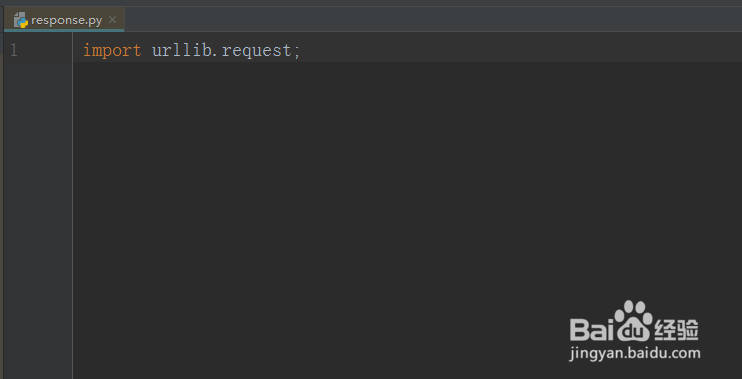
1、第一步,在新建的python文件中,导入urllib.request,注意确切的包,如下图所示:
2、第二步,再次调用urllib.request.urlopen(),传入的参数为一个网址,如下图所示:

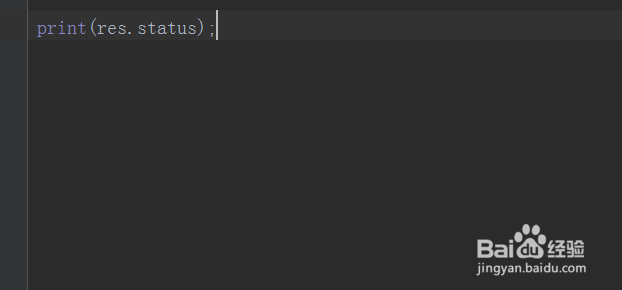
3、第三步,利用print()方法打印服务请求成功后的状态码,调用status属性,如下图所示:
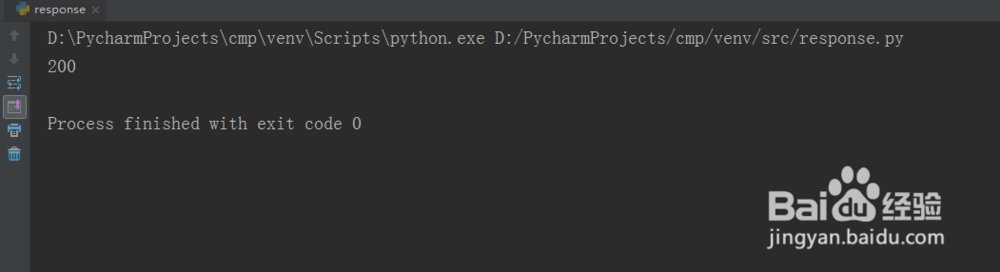
4、第四步,保存并运行这个python文件,可以看到打印出200结果,如下图所示:
5、第五步,再次获取服务器和网址请求信息头部,打印结果可以发现出现了编码,如下图所示:
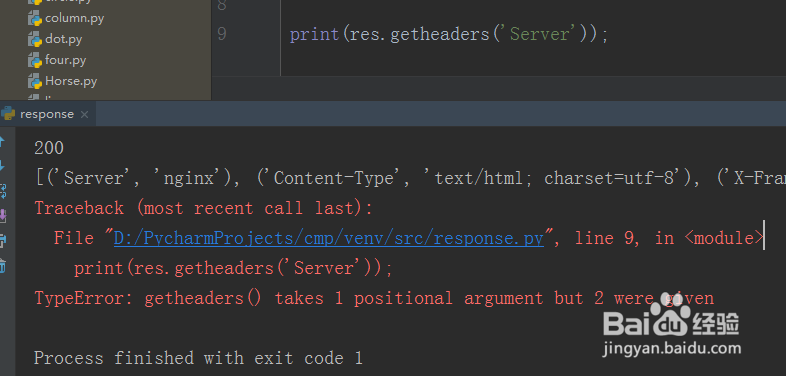
6、第六步,再次调用getheaders()方法,传入参数Server,结果发现出现了报错,如下图所示: